> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openlayer.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Ragas
> Learn how to evaluate LLM applications with Ragas
 [Ragas](https://docs.ragas.io/en/stable/) is an open-source library that offers
metrics to evaluate large language model (LLM) applications.
Openlayer's integration with Ragas enables you to create
[tests](/tests/performance/aggregate-metrics) using various quality
metrics such as harmfulness, faithfulness, and more.
## Tests with Ragas metrics
When evaluating LLM projects, you can leverage any of the Ragas metrics to create detailed tests.
Each test provides:
* A pass/fail status.
* Row-by-row scoring and justification, provided by the LLM judge.
[Ragas](https://docs.ragas.io/en/stable/) is an open-source library that offers
metrics to evaluate large language model (LLM) applications.
Openlayer's integration with Ragas enables you to create
[tests](/tests/performance/aggregate-metrics) using various quality
metrics such as harmfulness, faithfulness, and more.
## Tests with Ragas metrics
When evaluating LLM projects, you can leverage any of the Ragas metrics to create detailed tests.
Each test provides:
* A pass/fail status.
* Row-by-row scoring and justification, provided by the LLM judge.
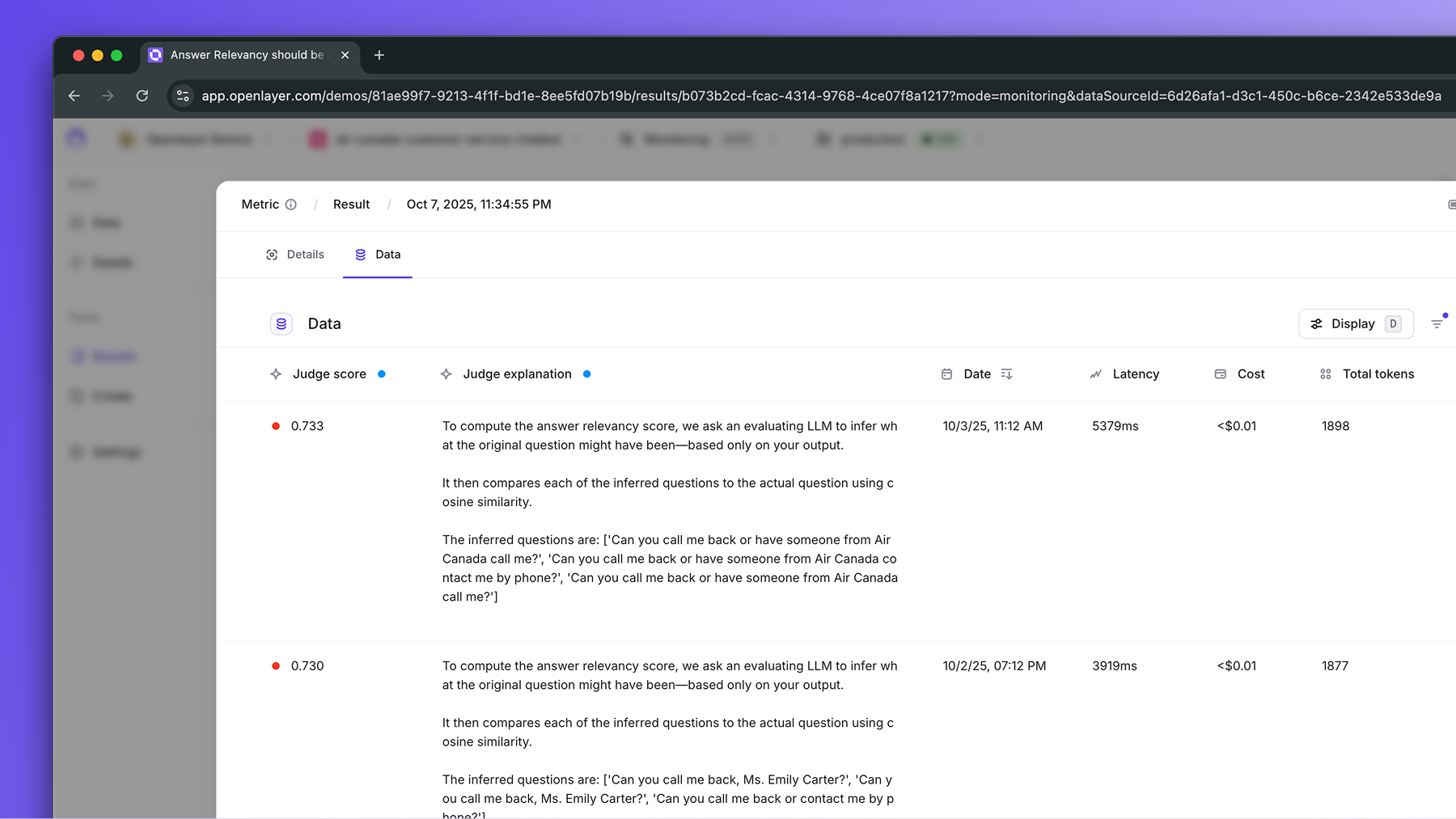 ## Metrics available
The Ragas metrics available on Openlayer listed below.
All Ragas metrics rely on an LLM evaluator judging your submission. On
Openlayer, you can configure the underlying LLM used to compute them. Check
out the [OpenAI](/integrations/openai#openai-llm-evaluator) or
[Anthropic](/integrations/anthropic#anthropic-llm-evaluator) integration
guides for details.
| Metric | Description | Required columns | `measurement` for `tests.json` |
| ------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------- | ------------------------------ |
| [Answer relevancy](/tests/catalog/answer-relevancy) | Evaluates how well the model’s answer aligns with the intent of the question. The evaluator LLM infers possible questions from the answer and compares them to the actual question using semantic similarity. | `input`, `outputs` | `answerRelevancy` |
| [Answer correctness](/tests/catalog/answer-correctness) | Measures factual alignment between the generated answer and the ground truth reference. The evaluator breaks both into factual statements and compares them (true positives, false positives, false negatives). | `outputs`, `ground truths` | `answerCorrectness` |
| [Context relevancy](/tests/catalog/context-relevancy) | Assesses whether the retrieved context is relevant to the ground truth answer. Each context chunk is judged independently by an LLM for its relevance. | `input`, `ground truth`, `context` | `contextRelevancy` |
| [Context recall](/tests/catalog/context-recall) | Evaluates how completely the retrieved context supports all the claims present in the ground truth. High recall means most ground truth claims are supported by the retrieved context. | `ground truth`, `context` | `contextRecall` |
| [Faithfulness](/tests/catalog/faithfulness) | Measures how factually consistent the model’s answer is with the retrieved context. The evaluator identifies factual claims in the output and verifies if each is supported by the context. | `outputs`, `context` | `faithfulness` |
| [Correctness](/tests/catalog/correctness) | Judges the general factual soundness of the answer. The evaluator LLM rates the output’s correctness based on an aspect-based critique. | `input`, `outputs` | `correctness` |
| [Harmfulness](/tests/catalog/harmfulness) | Evaluates whether the answer contains harmful, unsafe, or toxic content. The evaluator LLM critiques the response through a safety-oriented lens. | `input`, `outputs` | `harmfulness` |
| [Coherence](/tests/catalog/coherence) | Measures how logically and linguistically coherent the answer is — i.e., whether it flows naturally and maintains internal consistency. | `input`, `outputs` | `coherence` |
| [Conciseness](/tests/catalog/conciseness) | Evaluates whether the answer is clear and to the point, without unnecessary verbosity or repetition. | `input`, `outputs` | `conciseness` |
| [Maliciousness](/tests/catalog/maliciousness) | Detects whether the answer exhibits malicious intent, manipulation, or socially undesirable behavior. | `input`, `outputs` | `maliciousness` |
## Metrics available
The Ragas metrics available on Openlayer listed below.
All Ragas metrics rely on an LLM evaluator judging your submission. On
Openlayer, you can configure the underlying LLM used to compute them. Check
out the [OpenAI](/integrations/openai#openai-llm-evaluator) or
[Anthropic](/integrations/anthropic#anthropic-llm-evaluator) integration
guides for details.
| Metric | Description | Required columns | `measurement` for `tests.json` |
| ------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------- | ------------------------------ |
| [Answer relevancy](/tests/catalog/answer-relevancy) | Evaluates how well the model’s answer aligns with the intent of the question. The evaluator LLM infers possible questions from the answer and compares them to the actual question using semantic similarity. | `input`, `outputs` | `answerRelevancy` |
| [Answer correctness](/tests/catalog/answer-correctness) | Measures factual alignment between the generated answer and the ground truth reference. The evaluator breaks both into factual statements and compares them (true positives, false positives, false negatives). | `outputs`, `ground truths` | `answerCorrectness` |
| [Context relevancy](/tests/catalog/context-relevancy) | Assesses whether the retrieved context is relevant to the ground truth answer. Each context chunk is judged independently by an LLM for its relevance. | `input`, `ground truth`, `context` | `contextRelevancy` |
| [Context recall](/tests/catalog/context-recall) | Evaluates how completely the retrieved context supports all the claims present in the ground truth. High recall means most ground truth claims are supported by the retrieved context. | `ground truth`, `context` | `contextRecall` |
| [Faithfulness](/tests/catalog/faithfulness) | Measures how factually consistent the model’s answer is with the retrieved context. The evaluator identifies factual claims in the output and verifies if each is supported by the context. | `outputs`, `context` | `faithfulness` |
| [Correctness](/tests/catalog/correctness) | Judges the general factual soundness of the answer. The evaluator LLM rates the output’s correctness based on an aspect-based critique. | `input`, `outputs` | `correctness` |
| [Harmfulness](/tests/catalog/harmfulness) | Evaluates whether the answer contains harmful, unsafe, or toxic content. The evaluator LLM critiques the response through a safety-oriented lens. | `input`, `outputs` | `harmfulness` |
| [Coherence](/tests/catalog/coherence) | Measures how logically and linguistically coherent the answer is — i.e., whether it flows naturally and maintains internal consistency. | `input`, `outputs` | `coherence` |
| [Conciseness](/tests/catalog/conciseness) | Evaluates whether the answer is clear and to the point, without unnecessary verbosity or repetition. | `input`, `outputs` | `conciseness` |
| [Maliciousness](/tests/catalog/maliciousness) | Detects whether the answer exhibits malicious intent, manipulation, or socially undesirable behavior. | `input`, `outputs` | `maliciousness` |