How it works
1
Connect a data source
Integrating with Openlayer begins by connecting your warehouse or lakehouse (e.g.,
BigQuery, Databricks, Snowflake).See the Connect a data source guide for details.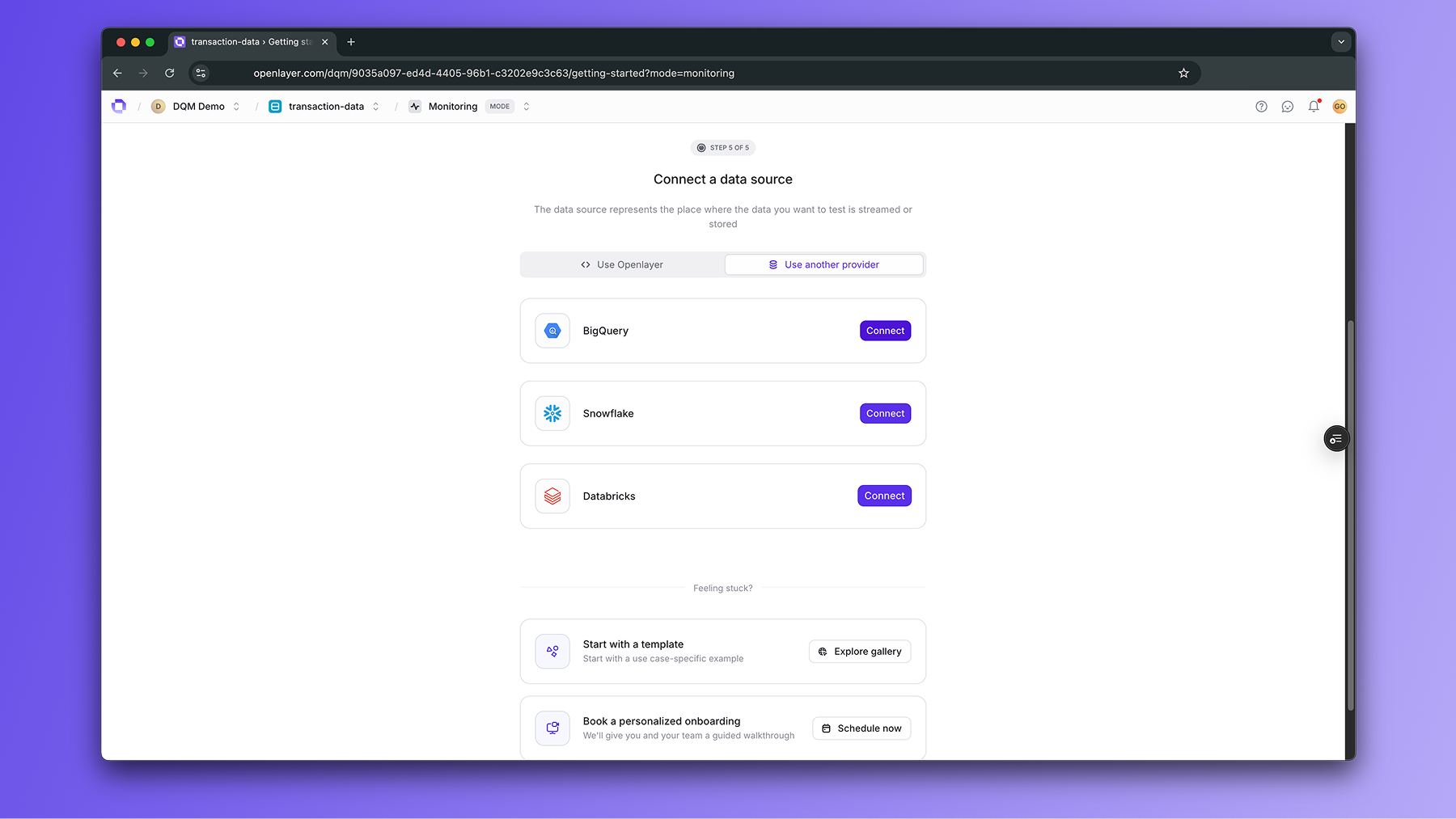
2
Select tables to monitor
After providing the necessary credentials, you can choose which tables you want to track.
Openlayer automatically profiles them, capturing schema, distributions, and summary statistics.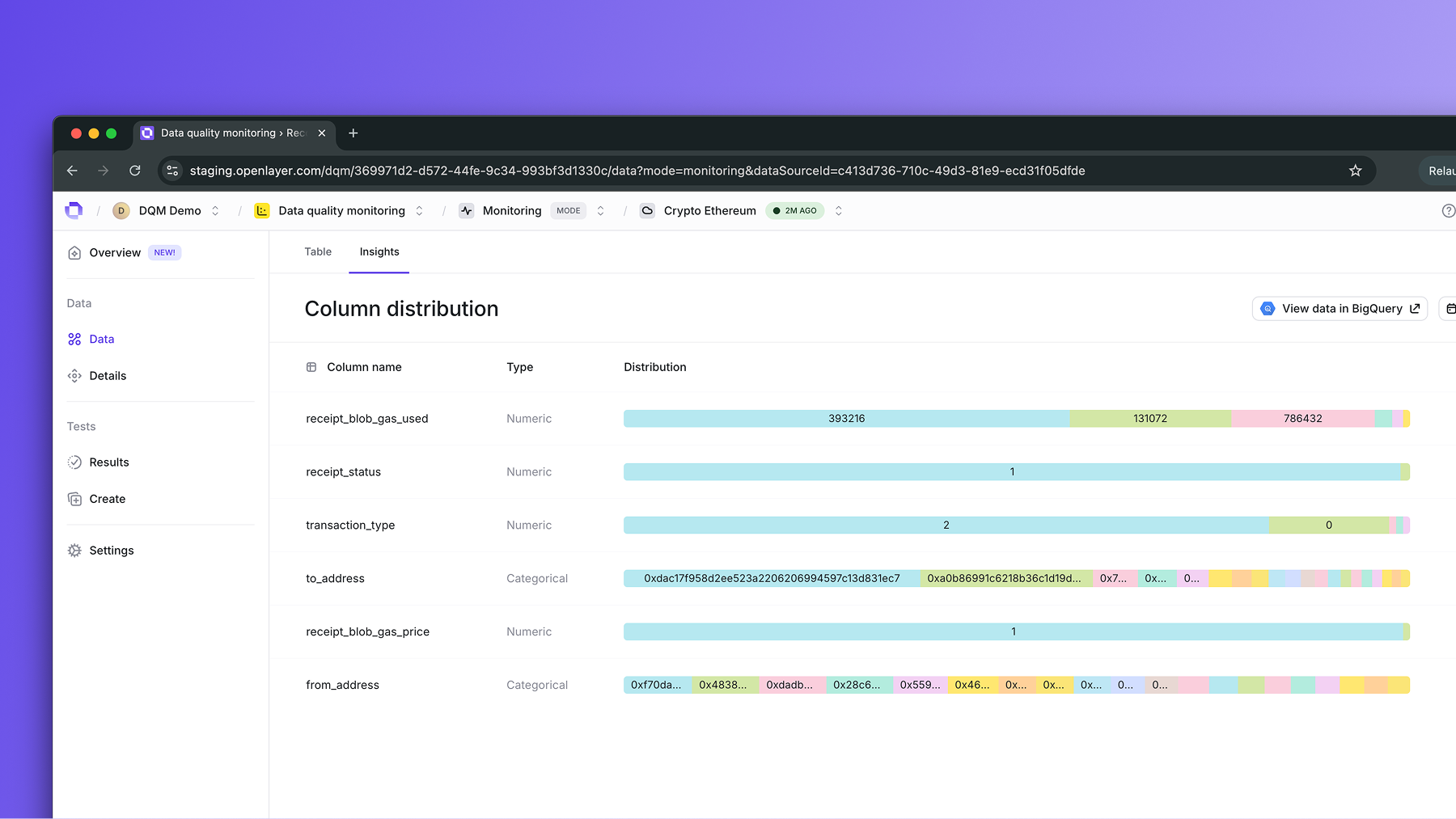
3
Set up tests
Add tests on top of your tables.
Common examples include schema checks (unexpected columns, type mismatches)
and anomaly detection (sudden spikes or drops in key metrics, missing values, etc.)Tests can run automatically at regular cadence on top of your tables.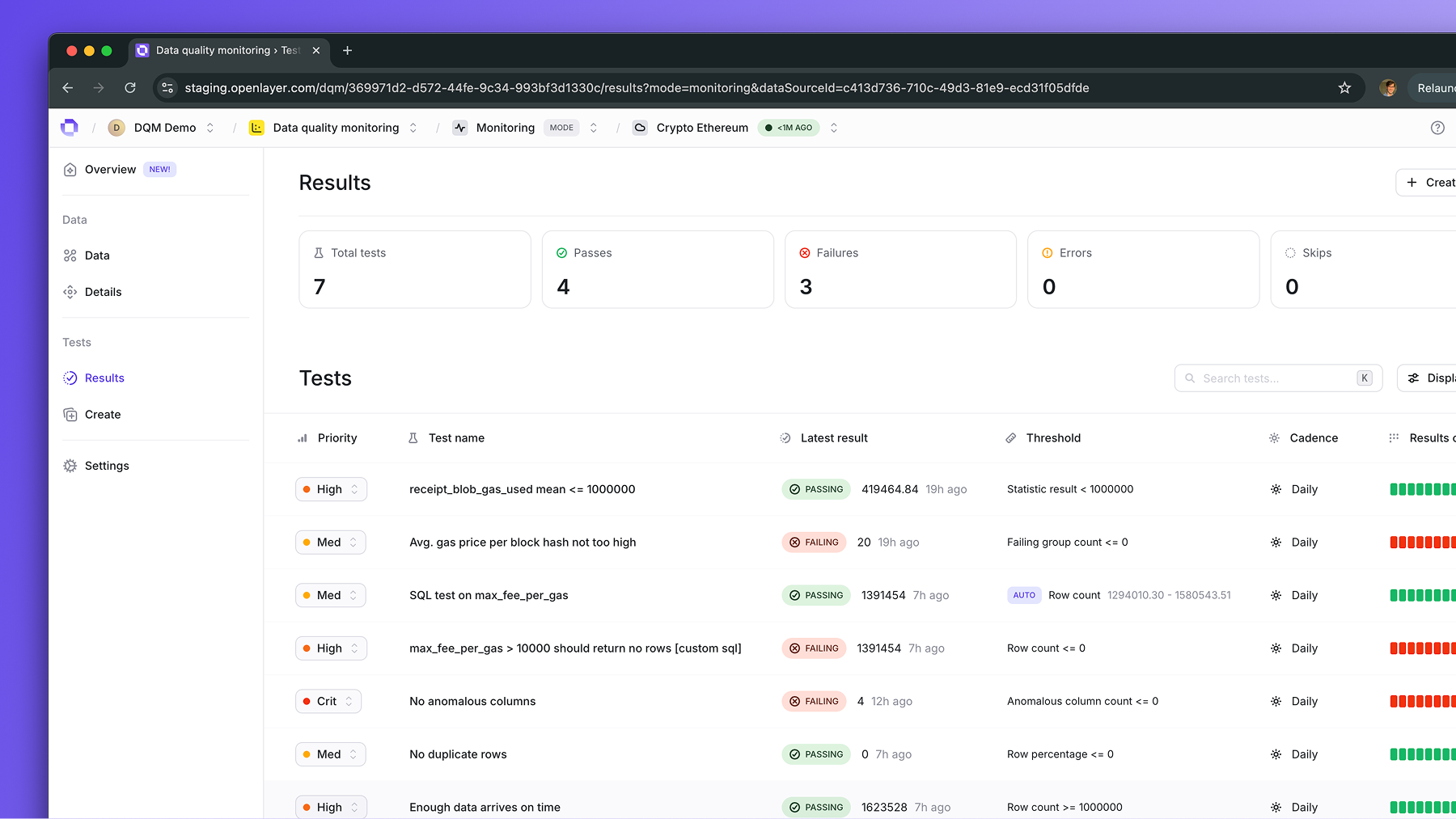
4
Get notified and act
Openlayer tracks test results over time and alerts you immediately when an anomaly is detected.
This way, you can respond before bad data propagates into models, dashboards, or production systems.
Next steps
By continuously monitoring table quality, Openlayer provides a feedback loop that keeps your data pipelines healthy and reliable. To try it out, check out the Connect a data source guide.FAQ
Do I need to copy data into Openlayer?
Do I need to copy data into Openlayer?
No. Openlayer connects to your warehouse or lakehouse and runs tests directly on your tables.
Data does not need to be replicated unless you explicitly choose to export results.
What data sources are supported?
What data sources are supported?
Today, Openlayer supports BigQuery, Databricks, and Snowflake. We’re expanding
coverage to additional warehouses and data lakes. See the Integrations
page for the latest list.
How is this different from Observability?
How is this different from Observability?
- Observability focuses on tracing your AI system in production and testing its live requests.
- Data quality monitoring focuses on the tables feeding those systems, helping you detect issues at the data source before they affect downstream models or apps.