
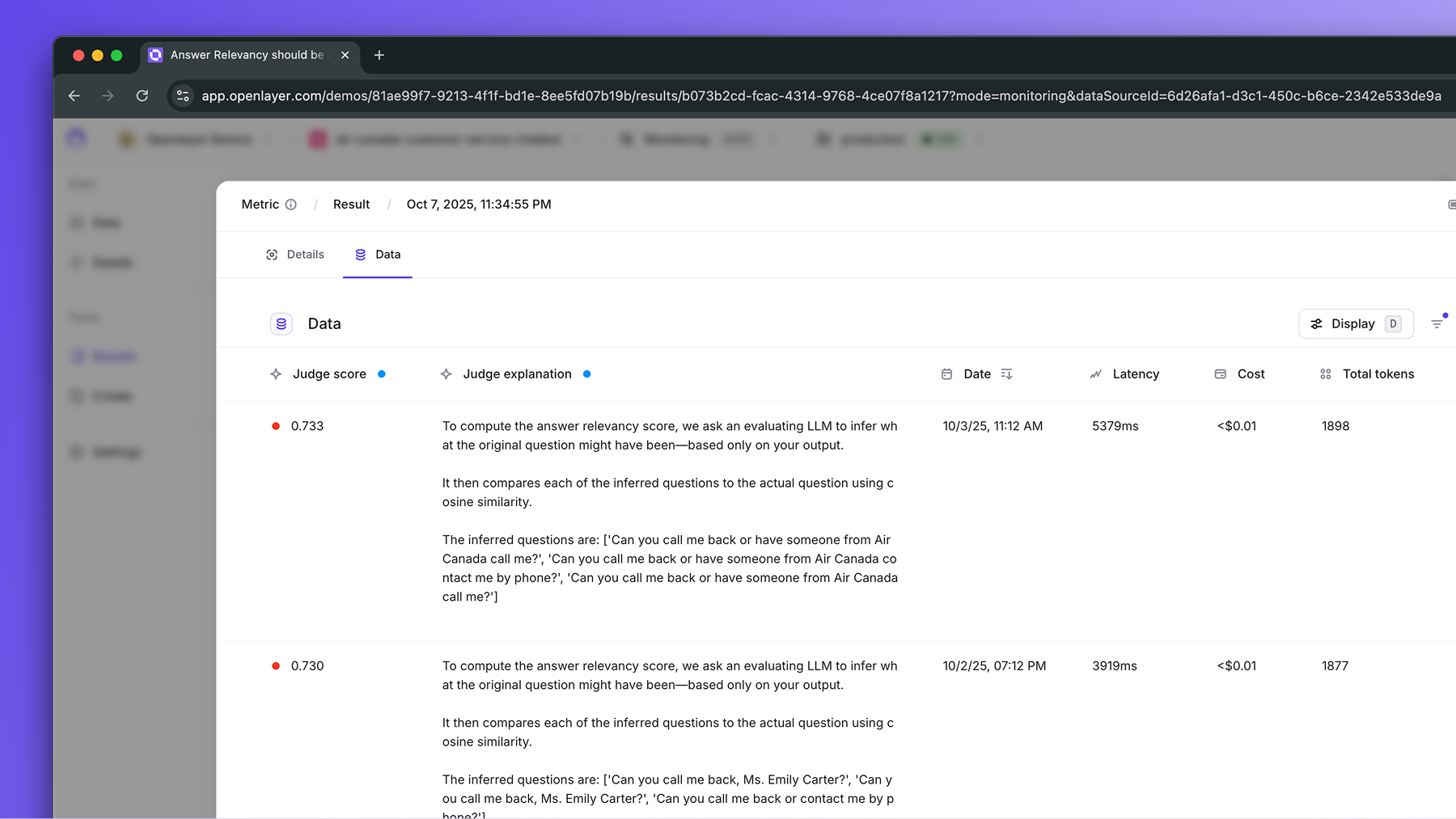
Tests with Ragas metrics
When evaluating LLM projects, you can leverage any of the Ragas metrics to create detailed tests. Each test provides:- A pass/fail status.
- Row-by-row scoring and justification, provided by the LLM judge.
Learn how to evaluate LLM applications with Ragas