How to integrate
Prerequisites:
- A project in Openlayer with monitoring mode enabled.
- An Openlayer API key.
- The Openlayer SDK in your language of choice installed.
1
Configure credentials
Set the following environment variables to tell the Openlayer SDKs where to upload
captured the traces:
2
Instrument the code you want to trace
Annotate all the functions you want to trace with Openlayer’s SDK.
Not using OpenAI? The steps are similar for other LLM providers and frameworks.
3
Use the instrumented code
All data that goes through the instrumented code is automatically
sent to the Openlayer platform, where your tests and alerts are defined.In the example above, if we call the resulting trace is: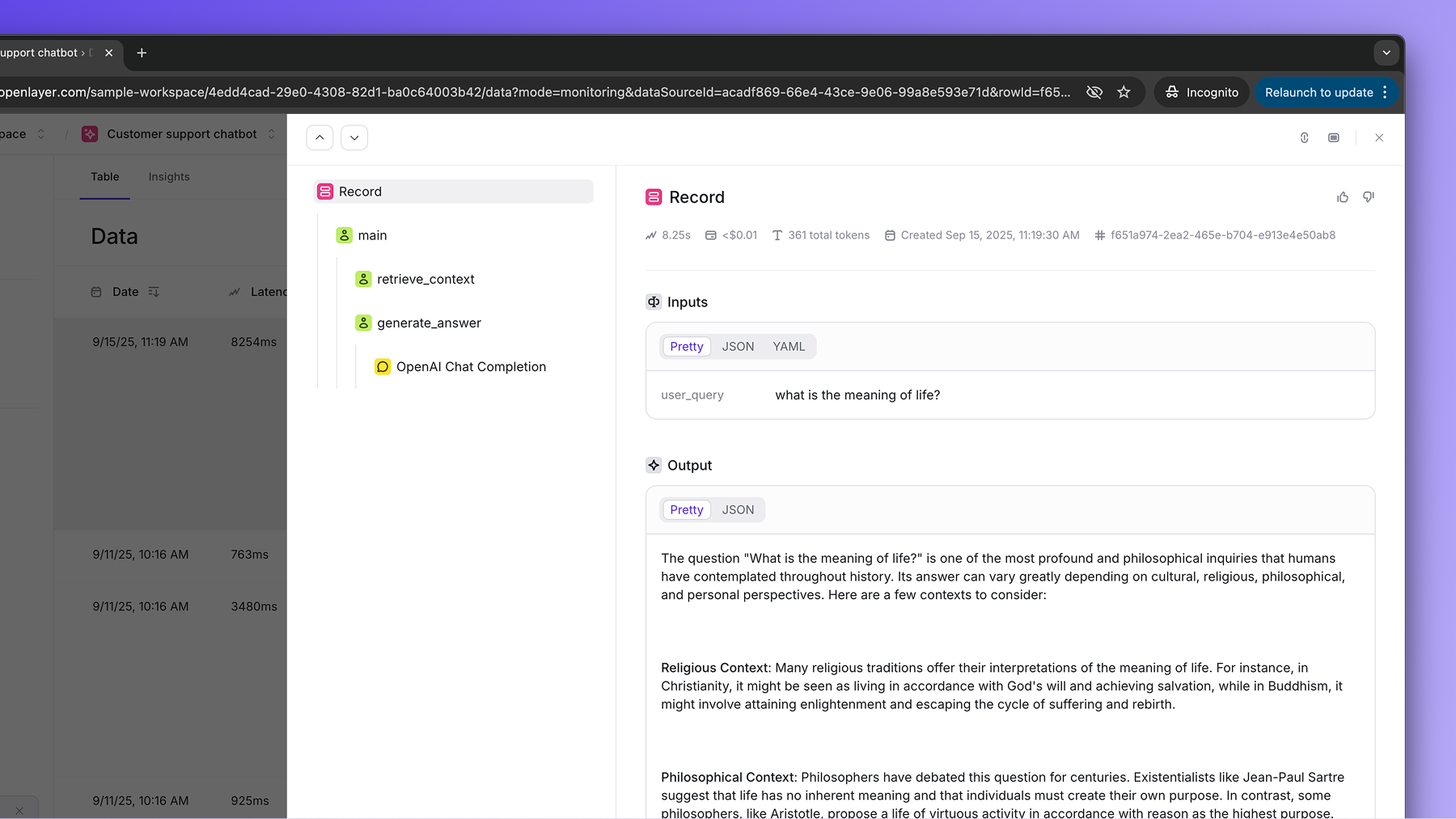
main:main function has two nested steps: retrieve_context, and
generate_answer. The generate_answer has a chat completion call within it. The cost,
number of tokens, latency, and other metadata are all captured automatically.Framework integrations
In the example above, we wrapped an OpenAI client. If you are using a different provider or framework, the process is the same but the wrapper might be different. Pick your stack below for the exact snippet:OpenAI
Azure OpenAI
Anthropic
LangChain
LangGraph
Amazon Bedrock
LiteLLM
Oracle OCI GenAI
Mistral AI
Groq
OpenAI Agents SDK
Don’t see your framework? Check out the Integrations
page for more details or reach
out.
What the instrumentation is doing
When you integrate, you are telling Openlayer two things:- “Here are my AI calls.” These are handled by Openlayer SDKs integrations for frameworks like OpenAI, Anthropic, or LangChain. Leveraging them, you get automatic capture of inputs, outputs, tokens, costs, latency, model parameters, and more.
-
“Here’s the rest of my workflow.” (Optional)
Retrieval steps, ranking, filtering, post-processing — anything that’s not an LLM call.
These are marked with the
@tracedecorator, so they show up as steps in the same trace.