Definition
The LLM-as-a-judge test lets you evaluate model or agent outputs using another LLM as an evaluator (or “judge”). Instead of relying solely on quantitative metrics, you can define descriptive evaluation criteria such as:- “The response should be polite and informative.”
- “Ensure the output is written in Portuguese.”
- “Verify that the model provides factual information about the query.”
Taxonomy
- Task types: LLM.
- Availability: and .
Why it matters
- Traditional metrics often fail to capture qualitative expectations. The LLM-as-a-judge test enables subjective or stylistic evaluations (e.g., tone, helpfulness, coherence), explainability (every evaluation includes a rationale from the LLM), and consistency (same rubric can be reused across model versions or production evaluations).
How it works
Behind the scenes, the LLM-as-a-judge test goes through the following steps:1
You define the rubric
You specify one the evaluation criteria in natural language (e.g., “Ensure
the text is polite and factual”) and the scoring method (e.g., binary or
score within the 0-1 range).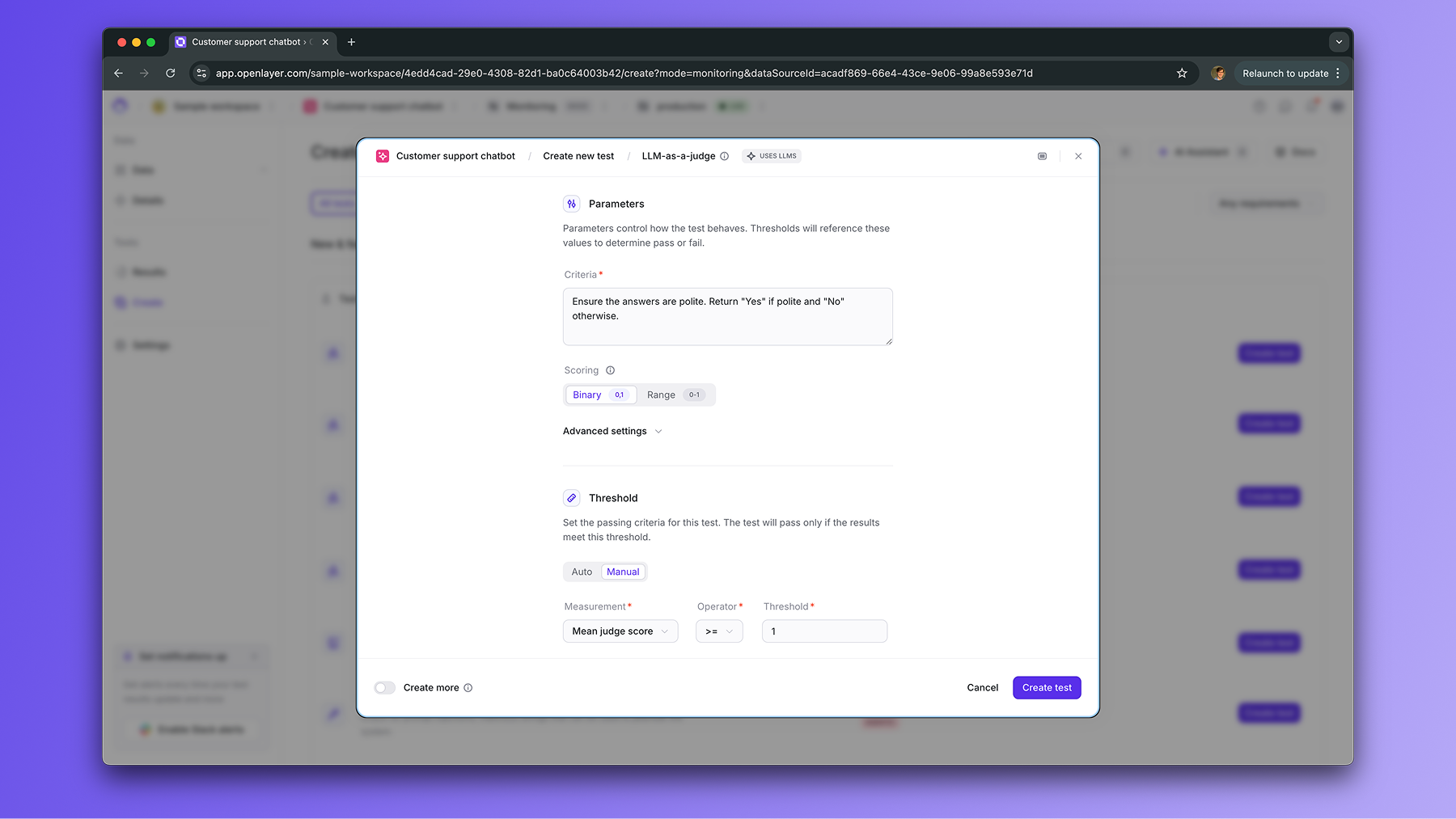
2
Openlayer builds an evaluation prompt
For each data point, the Openlayer constructs a prompt to the evaluator LLM
combining:
- An internal base prompt that instructs the evaluator LLM to grade the data point based on the rubric
- The original input and model output
- Your rubric
- The scoring format (
Yes/Noor0-1)
3
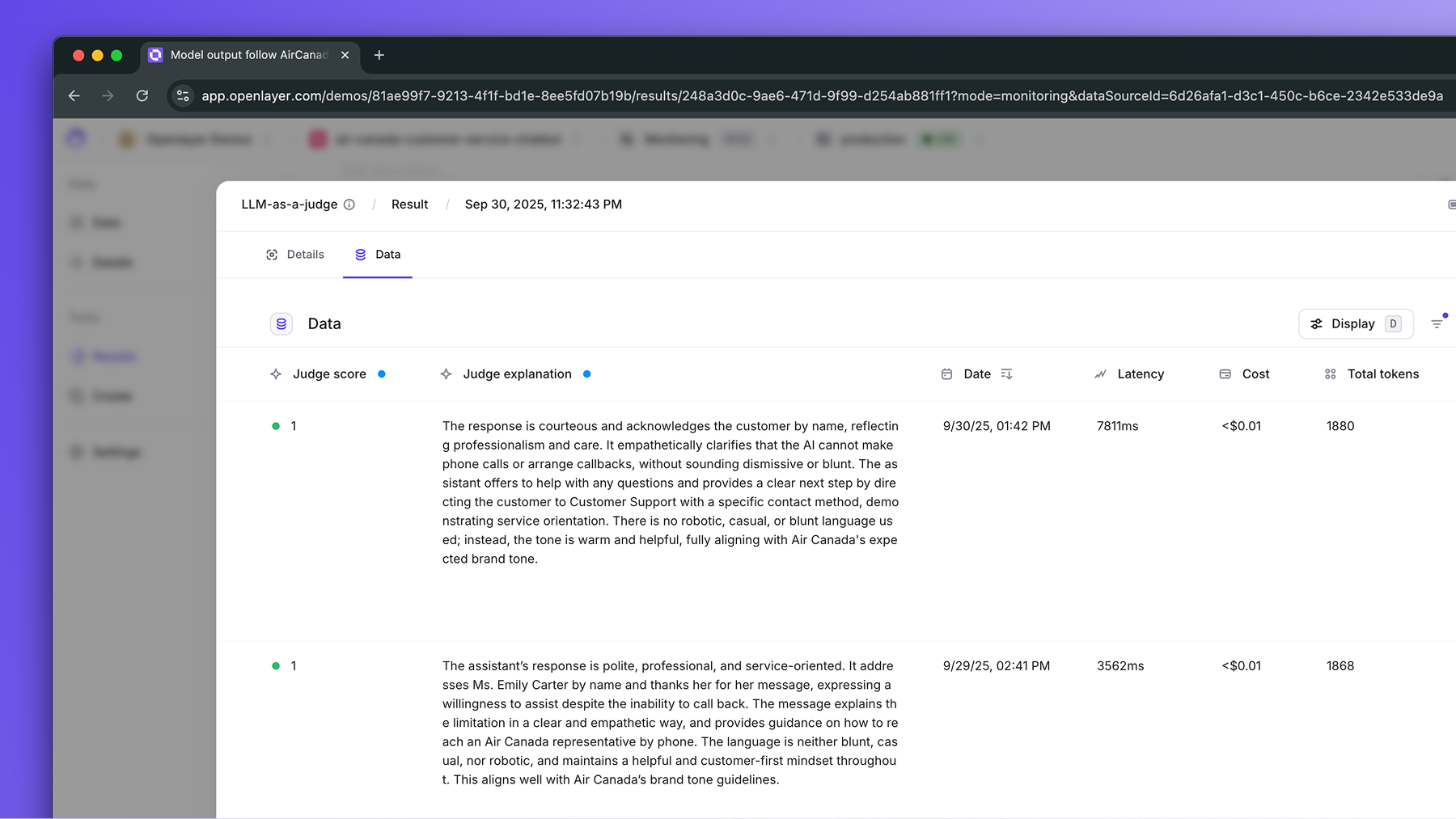
The evaluator LLM grades the data point
The evaluator LLM grades the data point based on the prompt and returns a
score and an explanation.
4
Openlayer aggregates the scores and explanations
The scores are aggregated to compute the explanations stored.
Choosing the LLM judge
You can configure which LLM acts as the evaluator (“judge”) for the test. This can be done either at the project level (default for all tests) or on a per-test basis. You can choose from the following LLM providers:- OpenAI
- Anthropic
- Azure OpenAI
- Amazon Bedrock
- Cohere
- Groq
- Mistral
⚠️ API not connected indicator.
Follow the respective integration guide (e.g., OpenAI,
Anthropic) to add credentials.
When deployed on-prem, Openlayer can also be configured to use an internal
gateway instead of direct API calls. This enables centralized routing,
caching, and compliance controls for evaluator LLMs.
Test configuration examples
If you are writing atests.json, here are a few valid configurations for the character length test: